En programación, una estructura de datos es una forma de organizar
un conjunto de datos elementales con el objetivo de facilitar su
manipulación. Un dato elemental es la mínima información que se tiene en
un sistema.
Una estructura de datos define la organización e interrelación
de éstos y un conjunto de operaciones que se pueden realizar sobre ellos.
Las operaciones básicas son:
Alta, adicionar un nuevo
valor a la estructura.
Baja, borrar un valor de la
estructura.
Búsqueda, encontrar un determinado valor en la
estructura para realizar una operación con este valor, en forma
SECUENCIAL o BINARIO (siempre y cuando los datos estén ordenados)...
En este blog encontraras en lenguaje C todos los
temas pertinentes a estructura de datos, iniciando desde el tema
de vectores hasta llegar a grafos. Esperamos que sea de tu total entendimiento,
ya que se explicara tema por tema utilizando un código base el
cual se podrá descargar siguiendo el enlace que estará en
su respectivo tema. Junto a esto estará añadido
un vídeo tutorial en el cual explicaremos paso a paso
cada código.
Un grafo en el ámbito de las ciencias de la computación es una estructura de datos, en concreto un tipo abstracto de datos (TAD), que consiste en un conjunto de nodos (también llamados vértices) y un conjunto de aristas que establecen relaciones entre los nodos. El concepto de grafo TAD desciende directamente del concepto matemático de grafo.
Existen diferentes implementaciones del tipo grafo: con una matriz de adyacencias (forma acotada) y con listas y multilistas de adyacencia (no acotadas).
Matriz de adyacencias: se asocia cada fila y cada columna a cada nodo del grafo, siendo los elementos de la matriz la relación entre los mismos, tomando los valores de 1 si existe la arista y 0 en caso contrario.
Matriz de adyacencia: las aristas del grafo se guardan en una matriz, indicando si un nodo tiene enlace directo con otro.
O\D
0
1
2
3
4
5
0
0
1
0
1
0
0
1
0
0
1
0
1
0
2
0
0
0
0
1
0
3
0
1
0
0
0
0
4
0
0
0
1
0
1
5
0
0
1
0
0
0
Lista de adyacencias: se asocia a cada nodo del grafo una lista que contenga todos aquellos nodos que sean adyacentes a él.
VIDEO TUTORIAL SOBRE GRAFOS.
Muchas gracias por la atencion prestada a este blog!!! :D
Un árbol AVL (llamado así por las iniciales de sus inventores: Adelson-Velskii y Landis) es un árbol binario de búsqueda en el que para cada nodo, las alturas de sus subárboles izquierdo y derecho no difieren en más de 1.
No se trata de árboles perfectamente equilibrados, pero sí son lo suficientemente equilibrados como para que su comportamiento sea lo bastante bueno como para usarlos donde los ABB no garantizan tiempos de búsqueda óptimos.
El algoritmo para mantener un árbol AVL equilibrado se basa en reequilibrados locales, de modo que no es necesario explorar todo el árbol después de cada inserción o borrado.
Inserción
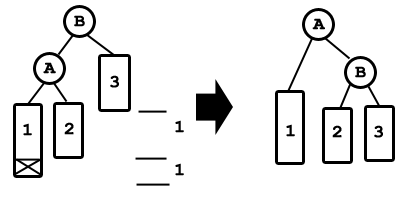
La inserción de un elemento en un árbol AVL es idéntica que en un árbol binario de búsqueda, la diferncia se encuentra en la comprobación que hay que realizar posteriormente en los árboles AVL. En un árbol AVL tras realizar la inserción hay que comprobar que se sigue manteniendo la condición de equilibrio, o lo que es lo mismo, que la altura del subárbol izquierdo y la del subárbol derecho difieran en una unidad o sean iguales. Si se produce un desequilibrio hay que re-equilibrar la estructura para que siga siendo un árbol AVL. Vamos a ver los mecanismos de re-equilibrado de los árboles AVL: Rotación simple.
El nodo insertado es el marcado con una X. Esta inserción provoca un desequilibro en el nodo B, que se soluciona con esta rotación.
Borrar
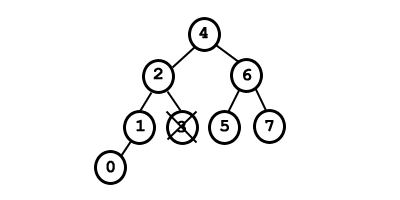
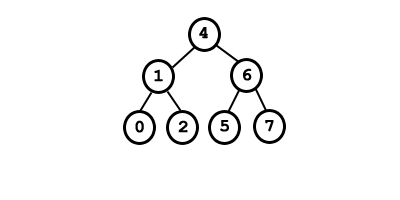
El procedimiento de borrado es el mismo que en el caso de árboles binarios de búsqueda. La diferencia se encuentra en el proceso de reequilibrado posterior. Este proceso es idéntico al que se realiza en la inserción, la única diferencia es que en la inserción tras realizar una rotación el árbol ya estaba equilibrado, mientras que en el borrado puede ser necesario realizar mas de una rotación. Ejemplo: Si eliminamos del siguiente árbol el nodo 3, el árbol se desequilibra en el nodo 2.
Una variante de los árboles B que permite realizar de forma
eficiente tanto el acceso directo mediante clave como el procesamiento en
secuencia ordenada de los registros, es la estructura de árbol B+ (propuesta
por Knuth [Knu97b]). Los árboles B+ almacenan los registros de datos sólo en
sus nodos hoja (agrupados en páginas o bloques), y en los nodos interiores y
nodo raíz se construye un índice multinivel mediante un árbol B, para esos
bloques de datos. Los árboles-B+ se han convertido en la técnica más
utilizada para la organización de archivos indizados
. CARACTERÍSTICAS DE ARBOLES
B+
Su principal característica es que todas las claves se encuentran
en las hojas. Los árboles B+ ocupan algo
más de espacio que los árboles B, pues existe duplicidad en algunas claves. En
los árboles B+ las claves de las páginas raíz e interiores se utilizan
únicamente como índices.
Otras características:
-La raíz almacena como mínimo un dato y como máximo m-1 datos.
-La página raíz tiene como mínimo dos descendientes.
-Las paginas intermedias tienen como mínimo (m-1)/2(Parte entera )
datos.
-Las páginas intermedias tienen como máximo m-1 datos.
-Todas las paginas hojas tienen la misma altura
-La información se encuentra ordenada.
PROPIEDADES DE ARBOLES B+
Un árbol B+ de orden n es una estructura formada por un conjunto
de bloques de registros ordenados por clave, que se almacenan a nivel de hoja, y un índice sobre un árbol B de orden n para los
bloques de registros (llamado conjunto índice).
Las restricciones de ocupación que determine el orden n del árbol
sólo afectarán al conjunto índice pero no a los bloques de registros, a los
cuales se les exigirá una ocupación mínima (y una máxima) pero no estará
relacionada con el orden del árbol.
Por tanto, las propiedades que estudiamos para los árboles B
pueden aplicarse a los árboles B+; la diferencia entre ambos está en el nivel
de las hojas. Además, los árboles B+ no almacenan en sus nodos interiores
direcciones de registros, sino sólo claves. Los registros se obtienen a nivel
de las hojas, donde se encuentran almacenados ordenados dentro de cada bloque.
Es decir, los nodos hoja del conjunto índice direccionan los nodos terminales
que contienen los datos.
Es de notar que los arboles-B+ ocupan un poco más de espacio que
los arboles-B, y esto ocurre al existir duplicidad en algunas claves. Sin
embargo, esto es aceptable si el archivo se modifica frecuentemente, puesto que
se evita la operación de reorganización del árbol que es tan costosa en los
arboles-B.
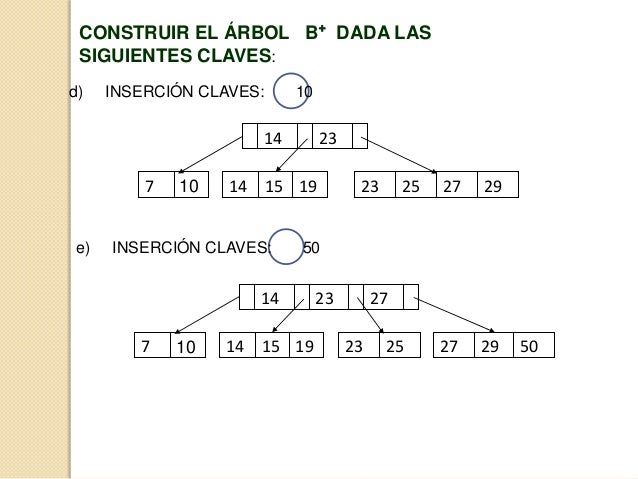
INSERCIÓN EN UN ÁRBOL B+
Los pasos a seguir para una
inserción son los siguientes:
Se ubica en la página
raíz.
Se evalúa si es una
página hoja
Si la respuesta es afirmativa, se
evalúa si no sobrepasa los límites de datos.
Si la respuesta es afirmativa,
entonces se procede a insertar el nuevo valor en lugar del correspondiente.
Si la respuesta es negativa, se
divide la página en dos, se sube una copia dela mediana a la página padre, si la página padre se encuentra llena se
debe de partir igual y así el mismo proceso hasta donde sea necesario, sieste proceso llega hasta la raíz la altura
del árbol aumenta en uno.
Si no es hoja, se compara el elemento a insertar con cada uno de los
valores almacenados para encontrar la página descendiente donde proseguir la
búsqueda. Se regresa al paso 1.
ELIMINACIÓN:
La operación de eliminación
en árboles-B+ es más simple que en árboles-B. Esto ocurre porque las claves a
eliminar siempre se encuentran en las páginas hojas. En general deben
distinguirse los siguientes casos:
Si al eliminar una clave, la
cantidad de llaves queda mayor o igual que [m/2] entonces termina la operación.
Las claves de los nodos raíz o internos no se modifican por más que sean una
copia de la clave eliminada en las hojas.
Si al eliminar una clave, la
cantidad de llaves queda menor que [m/2] entonces debe realizarse una
redistribución de claves, tanto en el índice como en las páginas hojas.
BÚSQUEDA:
La operación de búsqueda en
árboles-B+ es similar a la operación de búsqueda en árboles-B.
El proceso es simple, sin
embargo puede suceder que al buscar una determinada clave la misma se encuentre
en un nodo raíz o interior, en dicho caso no debe detenerse el proceso, sino que
debe continuarse la búsqueda con el nodo apuntado por la rama derecha de dicha
clave. • Por ejemplo, al buscar la clave 55 en el árbol-B+ de la figura 6 se
advierte que esta se encuentra en el nodo raíz. En este caso, debe continuarse
el proceso de búsqueda en el nodo apuntado por la rama derecha de dicha clave,
o sea, si se encuentra la clave Ki-1, debemos continuar la búsqueda por el
apuntador Pi.
Explicaremos lo árboles binarios; árboles cuyos nodos contienen dos ligas (ninguna, una, o ambas de las cuáles pueden ser NULL). El nodo raíz es el primer nodo del árbol. Cada liga del nodo raíz hace referencia a un hijo. El hijo izquierdo es el primer nodo del subárbol izquierdo, y el hijo derecho es el primer nodo del subárbol derecho.
Las definiciones a tener en cuenta son:
Raíz del árbol: Todos los árboles que no están vacíos tienen un único nodo raíz. Todos los demás elementos o nodos se derivan de él. El nodo raíz no tiene padre es decir, no es el hijo de ningún elemento.
Nodo, son los vértices o elementos del árbol.
Nodo terminal u hoja (leaf node) es aquel nodo que no contiene ningún subárbol.
A cada nodo que no es hoja se asocia uno o varios subárboles llamados hijos. De igual forma tiene asociado un antecesor llamado padre.
Los nodos de un mismo padre se llaman hermanos.
Todos los nodos tienen un solo padre – excepto la raíz – que no tiene padre.
Se denomina camino el enlace entre dos nodos consecutivos, y rama es un camino que termina en una hoja.
Cada nodo tiene asociado un número de nivel que se determina por la longitud del camino desde la raíz al nodo específico.
La altura o profundidad de un árbol es el número máximo de nodos de una rama. Equivale al nivel más alto de los nodos más uno. El peso de un árbol es el número de nodos terminales.
ejemplo.
Nodo raíz: nodo que no tiene padre. Este es el nodo que usaremos para referirnos al árbol. En el ejemplo, ese nodo es el 'A'.
Nodo hoja: nodo que no tiene hijos. En el ejemplo hay varios: 'F', 'H', 'I', 'K', 'L', 'M', 'N' y 'O'.
Recorrido en Inorden
Recorrer un árbol en Inorden consiste en primer lugar en recorrer el subárbol izquierdo en Inorden, luego se examina el dato del nodo raíz, y finalmente se recorre el subárbol derecho en Inorden. Esto significa que para cada subárbol se debe conservar el recorrido en Inorden, es decir, primero se visita la parte izquierda, luego la raíz y posteriormente la parte derecha.
Recorrido en Preorden:
Recorrer un árbol en preorden consiste en primer lugar, examinar el dato del nodo raíz, posteriormente se recorrer el subárbol izquierdo en preorden y finalmente se recorre el subárbol derecho en preorden. Esto significa que para cada subárbol se debe conservar el recorrido en preorden, primero la raíz, luego la parte izquierda y posteriormente la parte derecha.
Recorrido en Postorden:
Recorrer un árbol en Postorden consiste en primer lugar en recorrer el subárbol izquierdo en Postorden, luego serecorre el subárbol derecho en Postorden y finalmente se visita el nodo raíz. Esto significa que para cada subárbol se debe conservar el recorrido en Postorden, es decir, primero se visita la parte izquierda, luego la parte derecha y por último la raíz.
Los punteros permiten simular el paso por referencia, crear y manipular estructuras dinámicas de datos, tales como listas enlazadas, pilas, colas y árboles. Generalmente las variables contienen valores especificos. Los punteros son variables pero en vez de contener un valor especifico, contienen las direcciones de memoria de las variables a las que apuntan. Para obtener o modificar el valor de la variable a la que apuntan se utiliza el operador de indirección. Los punteros, al ser variables deben ser declaradas como punteros antes de ser utilizadas.
DECLARACIÓN
tipo *NombrePuntero;
Ejemplo:
int *ptr; -----------------------> puntero de tipo entero
char *ptr; -----------------------> puntero de tipo char
DEFINICIÓN Las listas doblemente enlazadas son un tipo de lista lineal en la que cada nodo tiene dos punteros, uno que apunta al nodo siguiente, y el otro que apunta al nodo anterior. Las listas doblemente enlazadas no necesitan un nodo especifico para acceder a ellas, ya que presentan una gran ventaja comparada con las listas enlazadas y es que pueden recorrerse en ambos sentidos a partir de cualquier nodo de la lista, ya que siempre es posible desde cualquier nodo alcanzar cualquier otro nodo de la lista, hasta que se llega a uno de los extremos. El puntero anterior del primer elemento debe apuntar hacia NULL (el inicio de la lista). El puntero siguiente del último elemento debe apuntar hacia NULL (el fin de la lista).
Para definir un elemento de la lista será utilizado el tipo struct. El elemento de la lista contendrá un campo dato, un puntero anterior y un puntero siguiente.
Los punteros anterior y siguiente deben ser del mismo tipo que el elemento, de lo contrario no van a poder apuntar hacia un elemento de la lista. El punteroanterior permitirá el acceso hacia el elemento anterior mientras que el puntero siguiente permitirá el acceso hacia el próximo elemento. DECLARACIÓN
La definición de colas es un conjunto de personas que realizan un orden uno tras otro para ser atendidos.
Un ejemplo de colas que podemos observar en la vida real a diario podría ser hilera de personas que esperan su turno para alguna cosa .
En este ejemplo las personas se atienden en el orden en que llegaron
DEFINICIÓN DE COLA
Una cola es una estructura de datos, caracterizada por ser una secuencia de elementos en la que la operación de inserción se realiza por un extremo y la operación de extracciónpor el otro. También se le llama estructura FIFO (del inglés First In First Out), debido a que el primer elemento en entrar será también el primero en salir.
Encolar: (añadir, entrar, insertar): se añade un elemento a la cola. Se añade al final de esta.
Desencolar: (sacar, salir, eliminar): se elimina el elemento frontal de la cola, es decir, el primer elemento que entró.
DECLARACIÓN
struct nodo
{
int num; // en este caso es un numero entero
struct nodo *siguiente;
};
struct cola
{
nodo *delante; //punteros que apuntan nodos de atras y adelante
nodo *atras;
};
A través de este link podrás descargar el código completo
Una pila (stack) es una estructura de datos, que consta de una serie de datos, La estructura pila se conoce como LIFO (last-in, first-out, último en entrar, primero en salir), que significa “último elemento introducido, primero sacado”.
Sol es posible insertar y eliminar nodos en uno de los extremos de la pila. esta operación se conoce como push y pop, respectivamente agregar y eliminar un nodo de la pila.
pop
borra el elemento en el tope del stack
push
agrega un elemento en el tope del stack
ESTRUCTURA
struct nodo{
int num;
struct nodo *siguiente; // este apunta al nodo siguiente.
};
typedef struct nodo *Pila; //estamos definiendo tipo de datos a struct nodo -- tipo pila para evitar confusiones.
El operador new proporciona espacio de almacenamiento persistente, similar pero superior a la función de Librería Estándar malloc. Este operador permite crear un objeto de cualquier tipo, incluyendo tipos definidos por el usuario, y devuelve un puntero (del tipo adecuado) al objeto creado.
FORMA DE DECLARA NEW:
Punto *p;
p = new Punto[100]; ----------------> se separa 100 espacios en la memoria para 100 datos